WSL2+KinD+Multipass: The Swarmenetes
Introduction
Local Kubernetes (K8s) single nodes cluster are so before COVID (read: 2019). The current “trend” is to create K8s multi-nodes clusters or, even better, High Availability (HA) clusters.
When dealing with K8s in Docker (KinD), both multi-nodes and HA are possible, however it will run only on our computer/laptop. And this is totally fine, I mean, that’s the original purpose “why” it has been created.
But what if a (crazy) Corsair wanted to create a multi-nodes cluster in a multi-hosts scenario? doing it only with the tools at hand and (literally) no YAML!!!
Starting to wonder how? is it even possible (specially the YAML part)?
The Corsair welcomes you to his new boat: the Swarmenetes.
Prerequisites
This blog post is intended to be followed, locally, from any OS (reaching Cloud Native nirvana). Still, in order to give you a background, the following technologies are the ones being used in this blog post:
- OS: Windows 10 Professional version 2004 - channel: release (not Insiders, as incredible as it can be)
WSL OS: Ubuntu 20.04 from the Windows Store
- WSL version: 2
WSL kernel: original version and updated via
wsl --update- Version: 5.4.51-microsoft-standard-WSL2
Virtualization:
- Local driver: Hyper-V
- Multipass guest OS: Ubuntu 20.04 LTS
Docker: installed on WSL2 distro
- Version: 19.03.13
- User type: anonymous
[Optional] Terminal: Windows Terminal
- Version: 1.3.2651.0
Building two nodes
Before we build our multi-nodes, multi-hosts KinD cluster, we need … well … at least two hosts.
For our first host, we will be using WSL2 with Ubuntu 20.04 as the distro. We will also install Docker, KinD and the Kubernetes tools directly on it.
We will not leverage Docker Desktop (see below: lessons learned).
The second host, as seen in the prerequisites, we will be using Canonical Multipass. This will allow us to run the exact same commands, independent of the OS running beneath. And same as for the first node, we will install all the components needed (Docker, KinD, Kubernetes tools)
Preparing the Swarm leader
The first step is to prepare the main host where, once the cluster will be created, we will run the commands to manage the cluster from there.
If the prerequisites are installed (it won’t be explain in this blog), then we already have an OS updated and Docker installed:

[Optional] Docker is not starting?
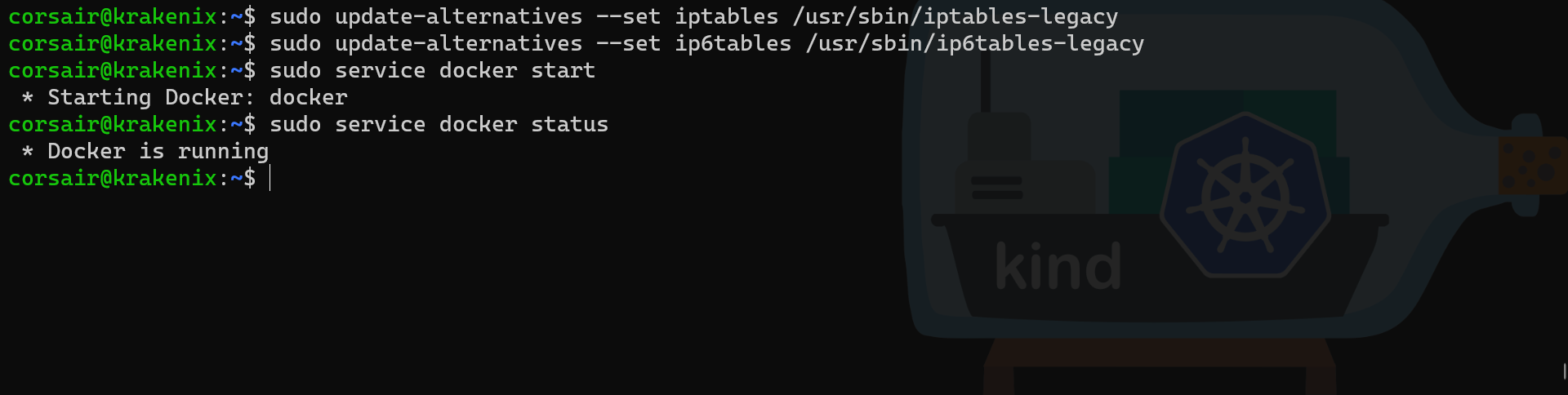
If the command sudo service docker status shows that Docker is not running, it might be due to an issue with iptables.
As described here, we can setup our WSL2 distro to use the legacy iptables, and start again Docker:
# Source documentation: https://github.com/WhitewaterFoundry/Pengwin/issues/485#issuecomment-518028465
# Update the iptables command
sudo update-alternatives --set iptables /usr/sbin/iptables-legacy
sudo update-alternatives --set ip6tables /usr/sbin/ip6tables-legacy
# Start the docker daemon
sudo service docker start
# Check if the docker daemon is running
sudo service docker status
Install KinD and Kubernetes tools
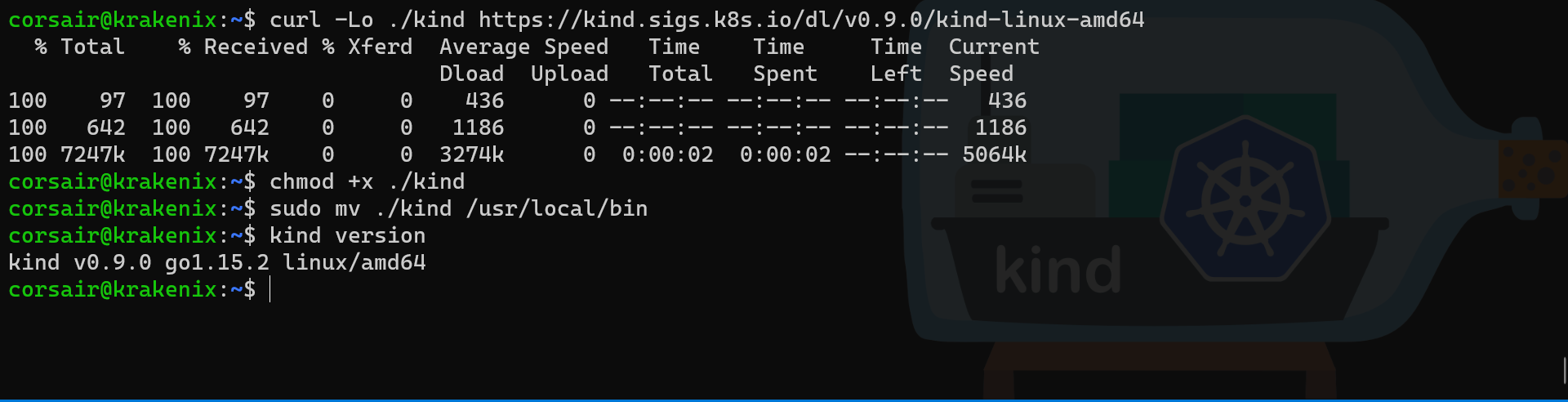
With Docker installed, we can now install KinD and the Kubernetes tools:
# Source documentation: https://kind.sigs.k8s.io/docs/user/quick-start/
# Current working directory: $HOME
# Download KinD binary
curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.9.0/kind-linux-amd64
# Change the permissions of the binary to be executable
chmod +x ./kind
# Move the binary to a directory contained in the $PATH variable
sudo mv ./kind /usr/local/bin
# Check if KinD has been correctly installed
kind version
# Source documentation: https://kubernetes.io/docs/tasks/tools/install-kubectl/
# Download Kubectl binary
curl -LO "https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl"
# Change the permissions of the binary to be executable
chmod +x ./kubectl
# Move the binary to a directory contained in the $PATH variable
sudo mv ./kubectl /usr/local/bin
# Check if kubectl has been correctly installed
kubectl version
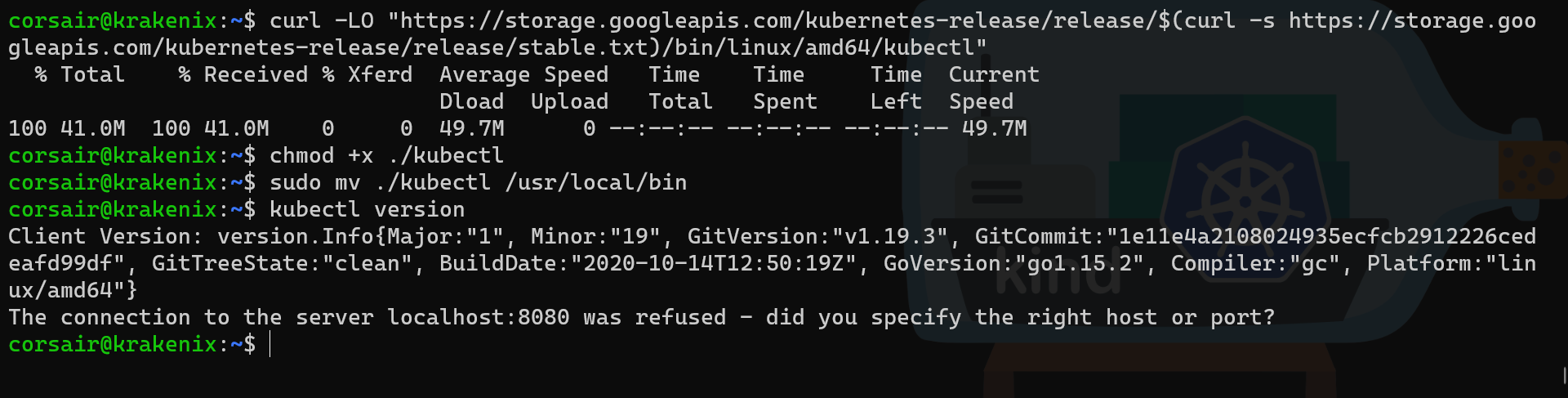
Note: the last command shows a connection refused. This is normal as there is still no Kubernetes server running. So we can consider it as a warning and not error
# Source documentation: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
# Install (potential) dependencies packages
sudo apt update && sudo apt install -y apt-transport-https curl
# Add the repository signed key
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
# Add the repository
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
# Refresh the listing of the repositories
sudo apt update
# Install kubeadm
sudo apt install -y kubeadm
# Check if kubeadm has been correctly installed
kubeadm version
Our first host is now ready, so time to prepare the second one.
Preparing the Swarm co-leader
The second step will be to create and launch a new Virtual Machine (VM), and in order to ensure we are not limited, we will tweak the options:
# Create a new VM with the following options:
# Command: multipass launch
# Options:
# lts: shortname for the OS and its version, which is Ubuntu 20.04 LTS
# --name kind1: sets the name of the VM
# --cpus 2: number of virtual CPUs assigned to the VM
# --mem 4G: amount of RAM assigned to the VM
# --disk 20G: creates a virtual Disk with 20Go
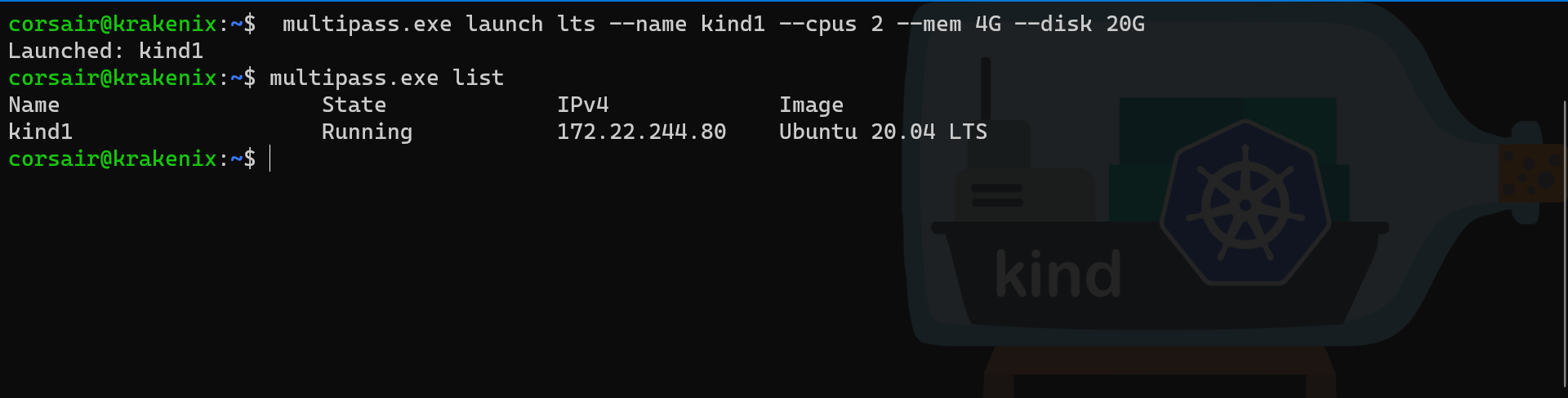
multipass.exe launch lts --name kind1 --cpus 2 --mem 4G --disk 20G
# Check if the VM has been correctly created
multipass.exe list
Once the VM is created, we can configure it by either running the commands with multipass.exe exec or entering the VM shell with multipass.exe shell.
For this blog post, we will enter into the shell as we will need to come back to it later on:
# Enter into the VM shell by providing the name of the VM
multipass.exe shell kind1

We can now update and upgrade the system and install Docker, KinD and the Kubernetes tools:
# Current working directory: $HOME
# Update the repositories
sudo apt update
# Upgrade the system with the latest packages version
sudo apt upgrade -y
# Source documentation: https://docs.docker.com/engine/install/ubuntu/
# Install dependencies
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
# Add Docker repository GPG key
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# Add Docker repository
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
# Install Docker and all needed components
sudo apt-get install docker-ce docker-ce-cli containerd.io
Note: as displayed in the screenshot, Docker was already installed in order to show the results more succintly
# Add the user to the docker group
sudo usermod -aG docker $USER
# Activate the change to the Docker group without logout/login
newgrp docker
# Check if Docker is running
docker version

# Source documentation: https://kind.sigs.k8s.io/docs/user/quick-start/
# Download KinD binary
curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.9.0/kind-linux-amd64
# Change the permissions of the binary to be executable
chmod +x ./kind
# Move the binary to a directory contained in the $PATH variable
sudo mv ./kind /usr/local/bin
# Check if KinD has been correctly installed
kind version
# Install the Kubernetes tools from the SNAP repository
sudo snap install kubectl --classic
sudo snap install kubeadm --classic
# Check if the Kubernetes tools have been correctly installed
kubectl version
kubeadm version
At this point, we have everything ready on the second host, and before you create our cluster, we need to setup the network in a “very special” way.
WSL finally meets Hyper-V
Since the launch of WSL2, there was a “small but painful” limitation: it could not see or connect to the Hyper-V networks. This means that the WSL2 distros and the Hyper-V VMs could simply not communicate.
In October this year (2020), Chris Jeffrey suggested a very nice workaround and that’s what we will use in this blog.
But first let’s see how the connection is not possible between WSL2 and Hyper-V VMs:
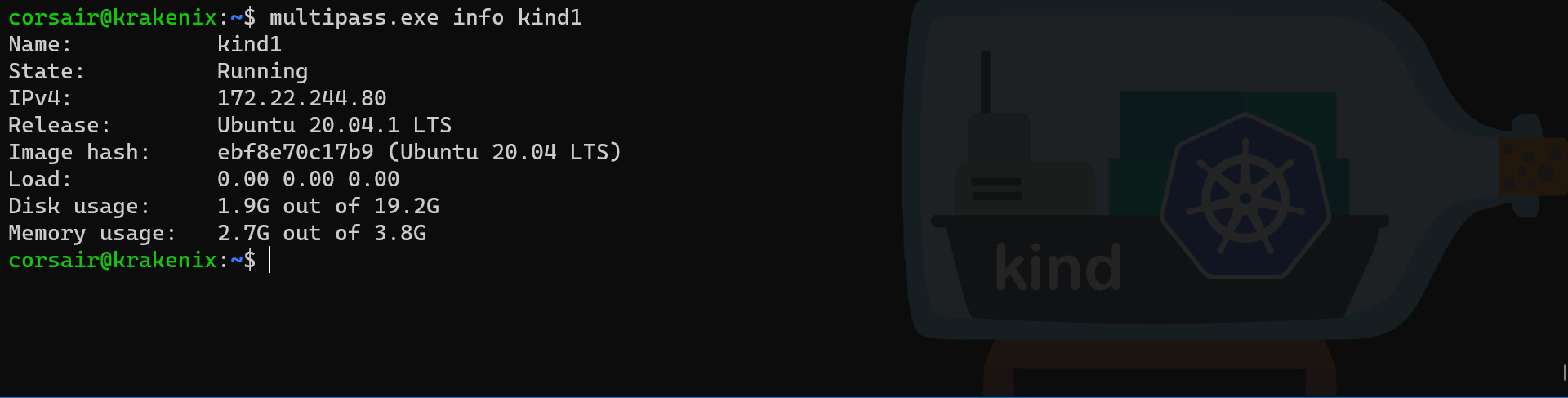
# Find the Multipass VM ip
# Command: multipass info
# Options:
# kind1: name of the VM
multipass.exe info kind1
# Try to ping the Multipass VM
ping 172.22.244.80
# Try to ssh into Multipass VM
ssh -l ubuntu 172.22.244.80
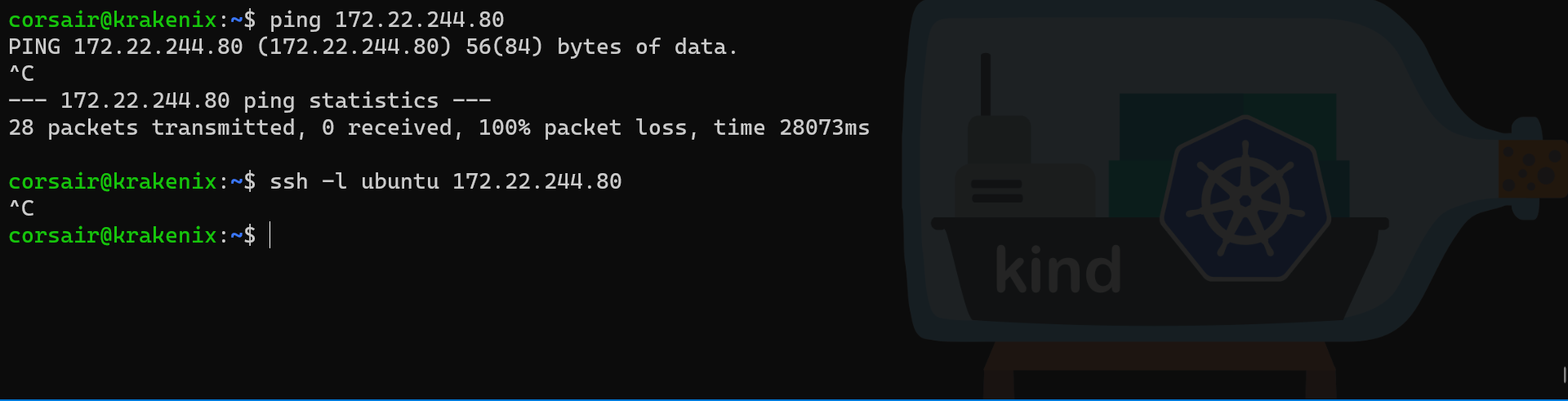
As we can see, no connectivity is currently possible between WSL2 and Hyper-V VMs.
Let us run the command from Chris blog and try again the connectivity tests:
# Source documentation: https://techcommunity.microsoft.com/t5/itops-talk-blog/windows-subsystem-for-linux-2-addressing-traffic-routing-issues/ba-p/1764074
# Run the powershell command directly from WSL
powershell.exe -c 'Get-NetIPInterface | where {$_.InterfaceAlias -eq "vEthernet (WSL)" -or $_.InterfaceAlias -eq "vEthernet (Default Switch)" } | Set-NetIPInterface -Forwarding Enabled'
# [Optional] if we rebooted Windows 10, we need to find again the Multipass VM IP
multipass.exe info kind1
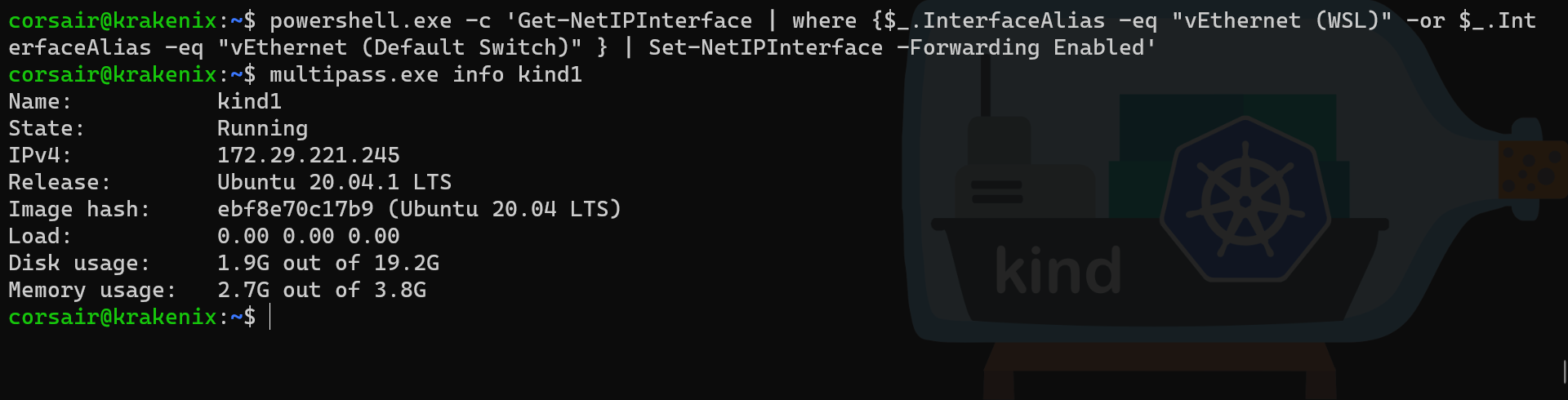
# Try to ping the Multipass VM
ping 172.29.221.245
# Try to ssh into Multipass VM
ssh -l ubuntu 172.29.221.245
Note: the SSH command ends in error as the Multipass VM SSH server is configured to only accept connections with a SSH key
Success! our WSL2 distro can now connect to the Hyper-V VMs which use the “Default Switch” for their Network virtual adapter.
Now it’s time to setup the network that will be used for our KinD multi-nodes cluster.
A Swarm-y network
Right now, even if WSL2 sees the Hyper-V VMs, both of them have their own Docker network setup, which are private to the host. So what we need, is a common network which our containers will use in order to be able to communicate “easily” between them.
If only we had something to help us making it simple, right? Well we do have this technology at hand since quite a long time (Cloud Native years): Docker Swarm overlay network!
The Swarm creation
With the connectivity enabled between WSL2 and Hyper-V, we can create a Docker Swarm cluster between the two nodes.
In order to use the exact same network, we need our two nodes to be manager nodes. We will also need to ensure we use the IP assigned to the WSL2 host eth0 interface, as it is the one that Hyper-V sees:
# Get the eth0 IP address
ip addr show eth0 | grep -m1 inet
# Initialize the swarm on the main node with the eth0 IP address
docker swarm init --advertise-addr=172.28.115.62
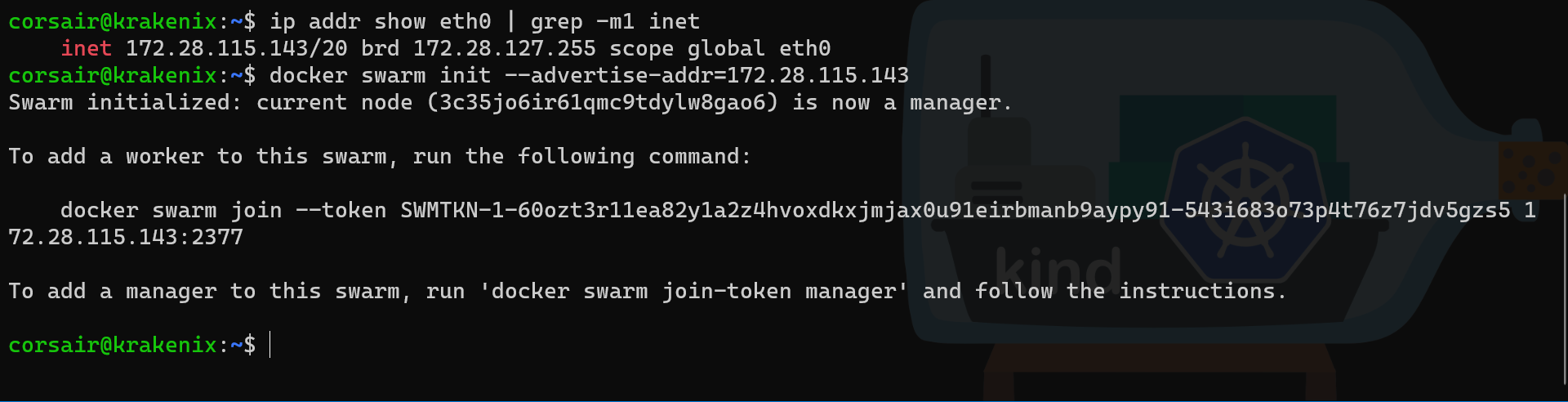
# Run the join command on the Multipass VM
docker swarm join --token SWMTKN-1-60ozt3r11ea82y1a2z4hvoxdkxjmjax0u91eirbmanb9aypy91-543i683o73p4t76z7jdv5gzs5 172.28.115.143:2377
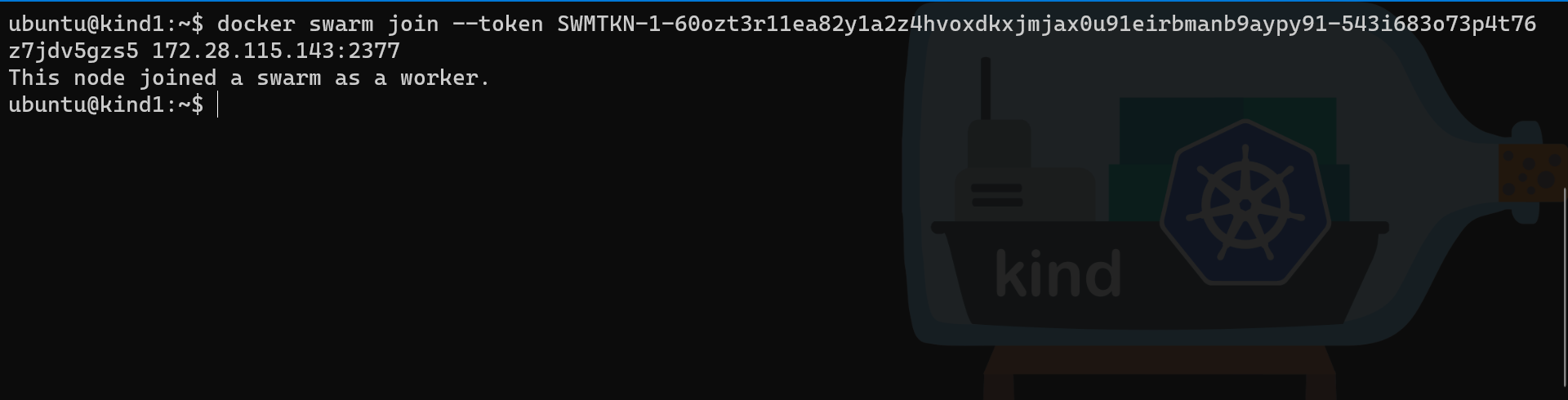
Both nodes are now part of the Swarm cluster and we can now promote the second node and check their status from the primary manager node :
# Check the current status for both nodes
docker node ls
# Promote the second node as manager
docker node promote kind1
# Check if the status has been correctly updated
docker node ls
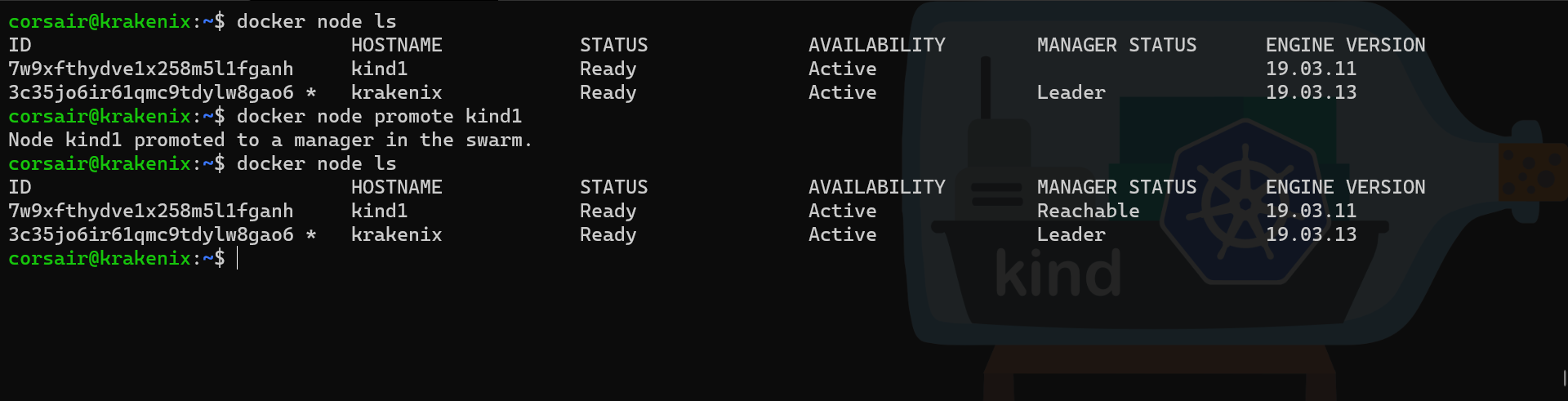
The two nodes Swarm cluster is now created. We can create our network.
A KinD and attachable network
Now that we have our nodes connected, we still need to use a common network. By default, Docker Swarm creates two networks as described in the official documentation and cited here:
- an overlay network called
ingress, which handles control and data traffic related to swarm services. When you create a swarm service and do not connect it to a user-defined overlay network, it connects to theingressnetwork by default. - a bridge network called
docker_gwbridge, which connects the individual Docker daemon to the other daemons participating in the swarm.
However, both networks are exclusively used for deploying Docker Swarm services or stacks. In our case, we need to attach “standalone containers” to a Swarm network.
Thankfully, we can create our own network and make it attachable by the containers directly:
# Source documentation: https://docs.docker.com/network/network-tutorial-overlay/#use-an-overlay-network-for-standalone-containers
# Create a new overlay network
# Command: docker network create
# Options:
# --driver=overlay: specifies the network driver to be used
# --attachable: allows containers to use this network
# kindnet: name of the network
docker network create --driver=overlay --attachable kindnet
# Check if the network has been created
docker network ls
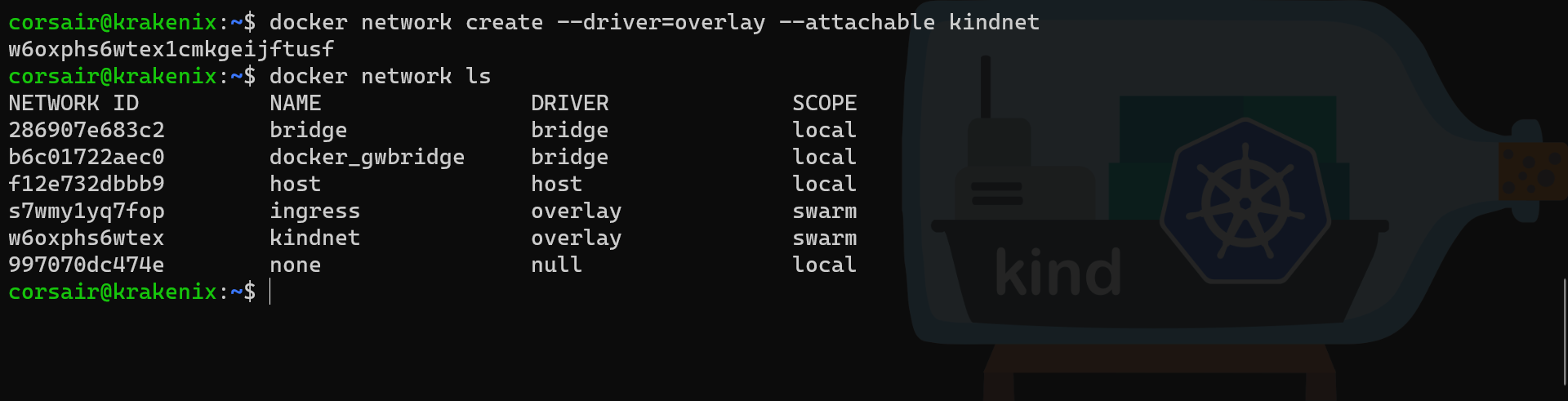
# Check on the second manager node is the network is visible
docker network ls
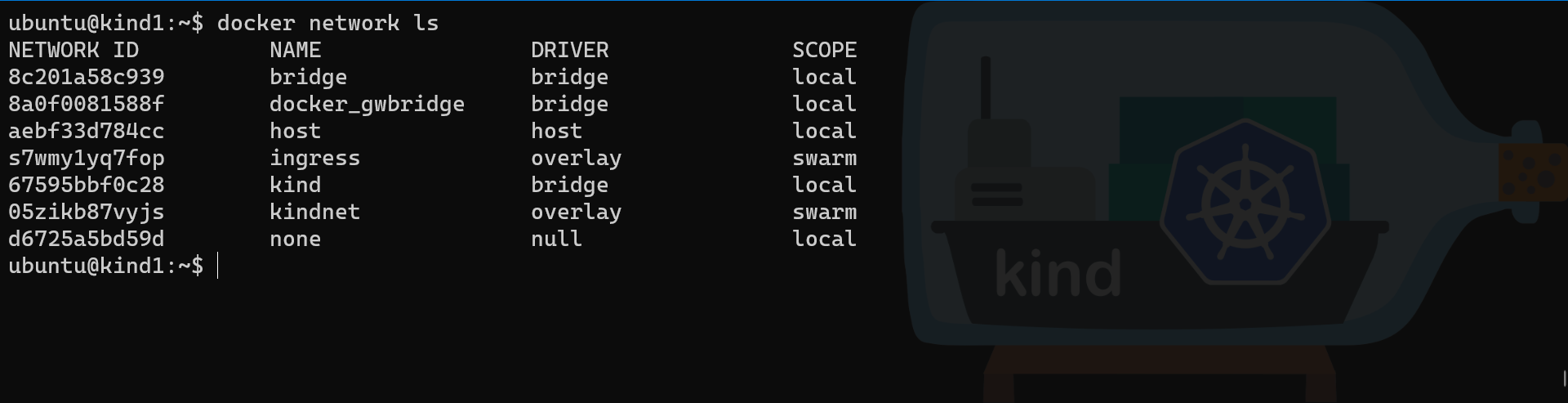
We have now configured all the components and can create our multi-nodes KinD cluster.
Swarmenetes: full sail!
The first step will be to create our two KinD clusters and then we will reset the one on the second manager node and will have it join the KinD cluster on the primary manager node.
Once again, this section has been made possible thanks to a great human being: the KinD Super Hero and CNCF Ambassador Duffie Cooley. He took time over his schedule to answer silly Corsair’s questions and help unlocking the Pandora box.
A single node to start slowly
Before we create the multi-nodes cluster, let us understand how KinD works and what could be an issue when going multi-nodes. And we will see what workaround/solution will be used to avoid the said issues.
OK, let us decrypt this enigmatic sentence by creating a single node KinD cluster:
# Create a single node KinD cluster
kind create cluster
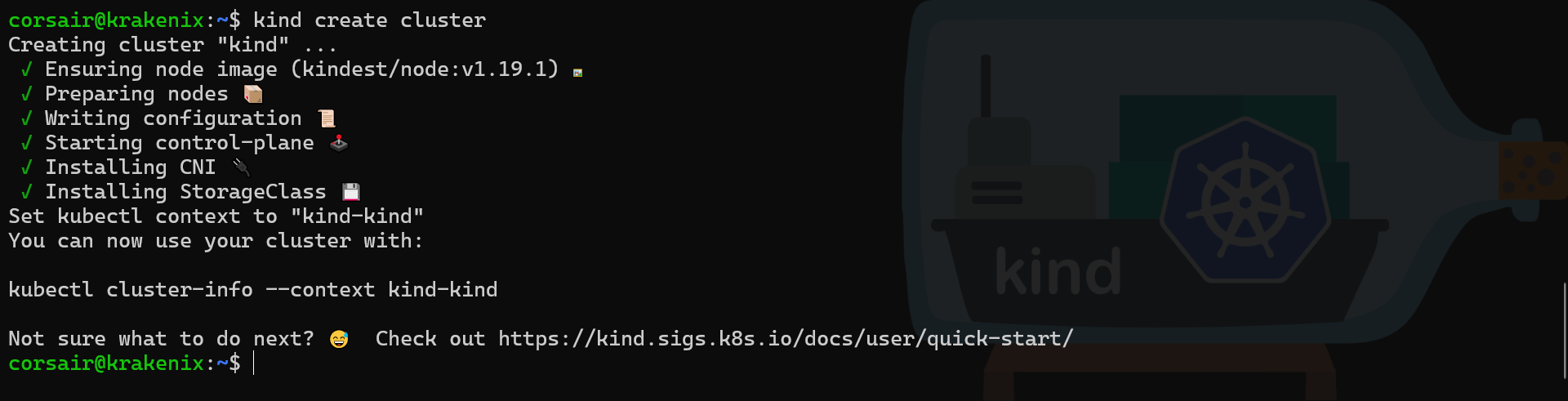
# Check if the cluster is running
kubectl cluster-info --context kind-kind
# Check the node from KinD perspective
kind get nodes
# Check the node from Kubernetes perspective with a detailed output
kubectl get nodes -o wide
# Check which server address is used in the ".kube/config" file
grep server .kube/config
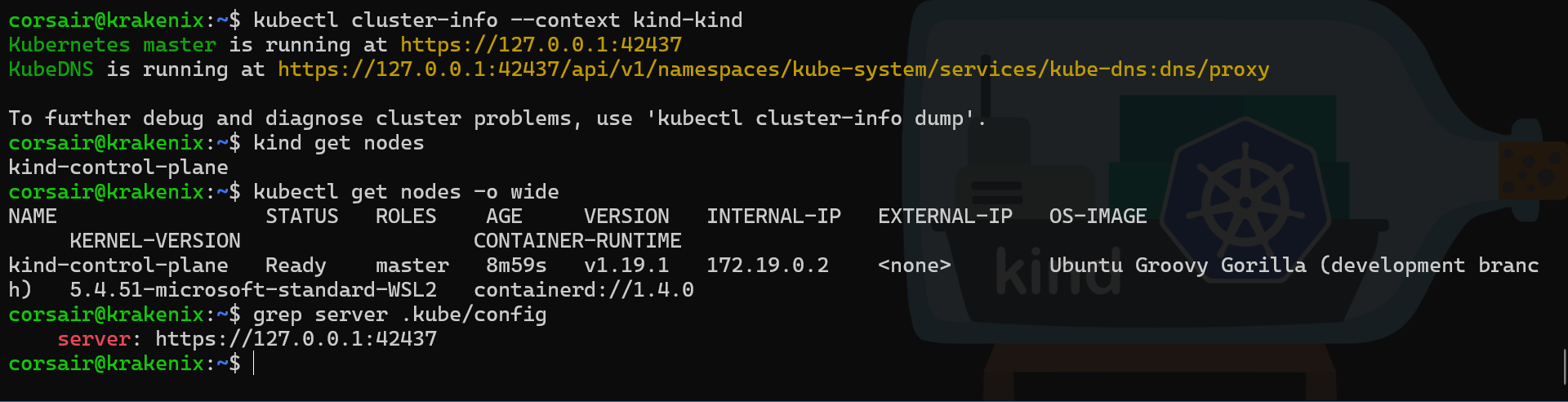
Everything is working well, however the config file shows that our server connection string is using the local IP (127.0.0.1).
And if we try to generate a join token, this will also be the IP used:
# Create a new join token
kubeadm token create --print-join-command
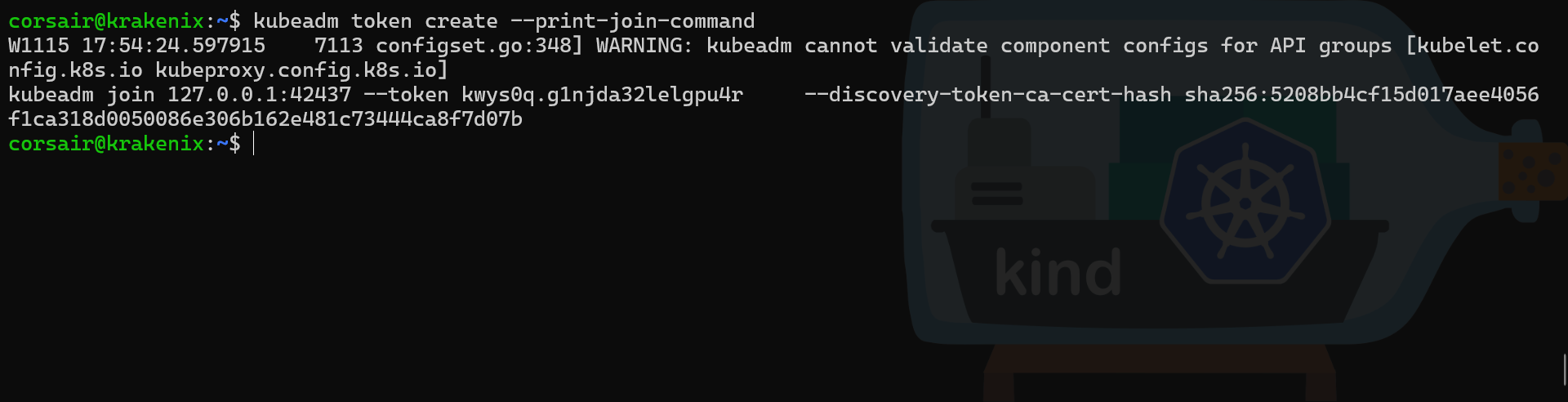
And if we try to run this command in our worker node then it will fail as it will try to connect locally.
Well, this actually not the full history. Let us have a deeper look into the container running the K8s cluster.
KinDly show the config
When we create a K8s cluster with KinD, it generates an “external” config to be used outside the container. If we follow the rabbit (read: the server connection string in the .kube/config file), we will see the local IP with a random port. This port is actually bound to the standard K8s defaut API server port 6443:
# Check the running container
docker ps
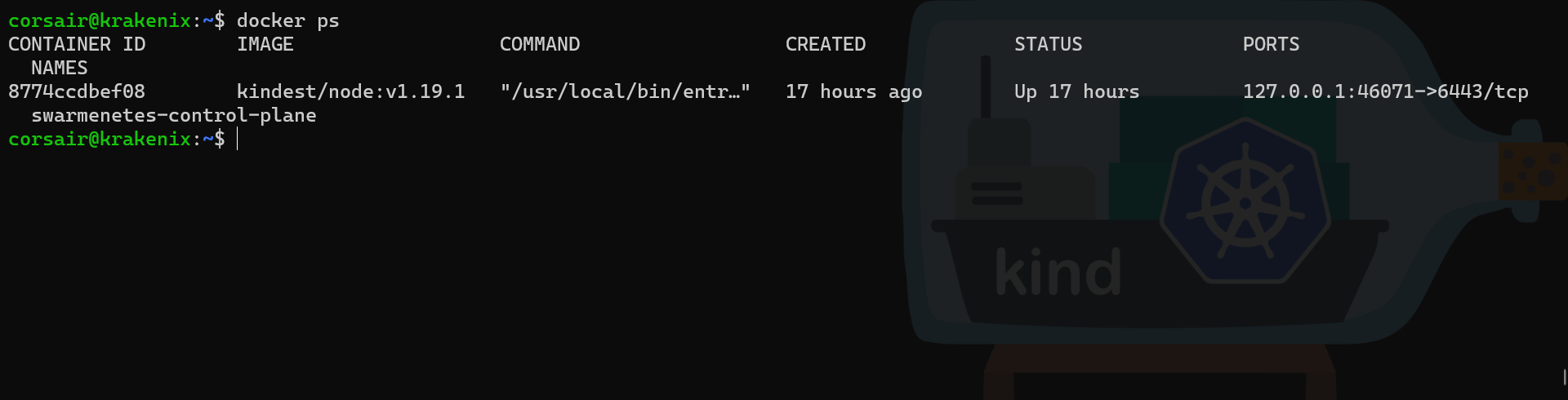
This configuration, as said before, will not help us, however if we check the “internal” configuration, then we get way more interesting data:
# Get the server connection string from the "admin.conf" inside the container
docker exec swarmenetes-control-plane grep server /etc/kubernetes/admin.conf
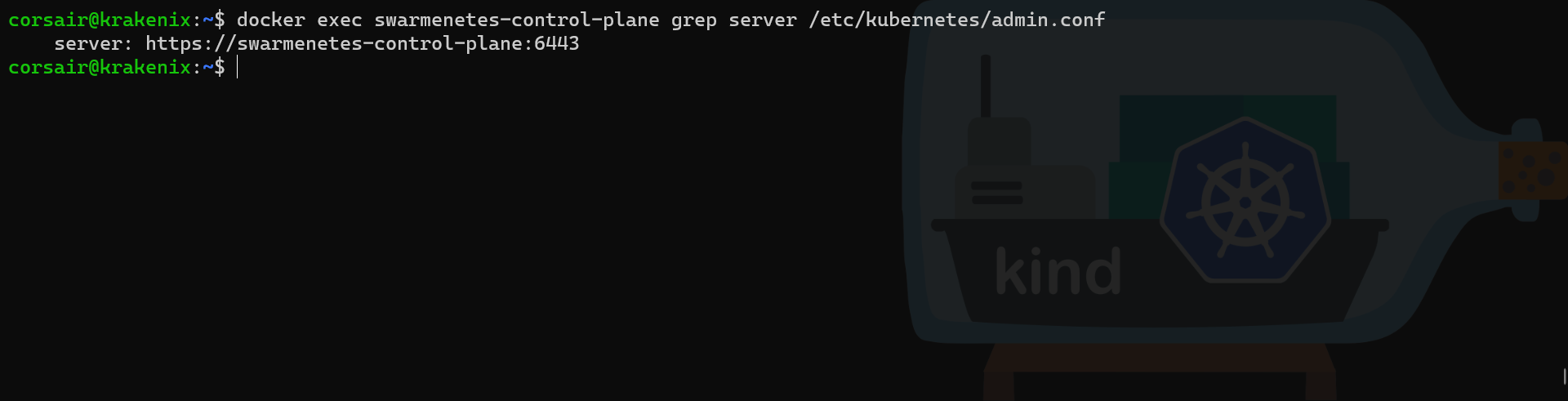
Perfect! the server connection string inside the container is set against a DNS name and not an IP. So if we go to the very end of this rabbit hole, we should get a join command that we will be able to reuse in another node:
# Check if kubeadm is pre-installed in the container
docker exec swarmenetes-control-plane kubeadm version
# Create a new join token from inside the container
docker exec swarmenetes-control-plane kubeadm token create --print-join-command
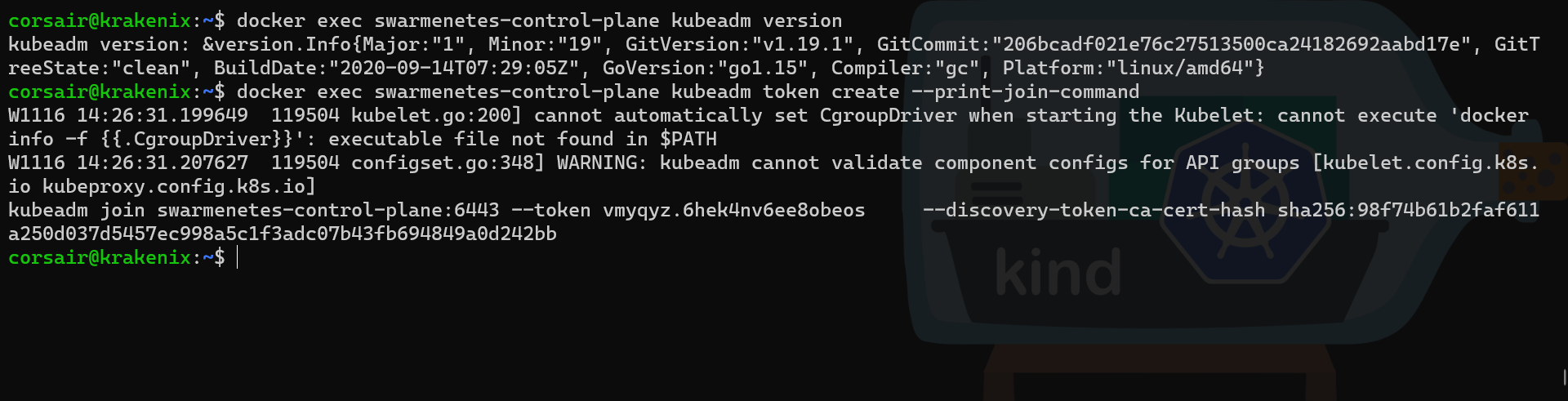
As expected, the join command has the DNS name seen in the server connection string and we will be able to reuse it.
It’s time to put everything together and build our multi-nodes on multi-hosts KinD cluster.
Cleaning before the grand finale
Let us delete this cluster as it is not using the right network:
# Check the name of the cluster created
kind get clusters
# Delete the running cluster
kind delete cluster
# Check if the cluster is deleted
kind get clusters
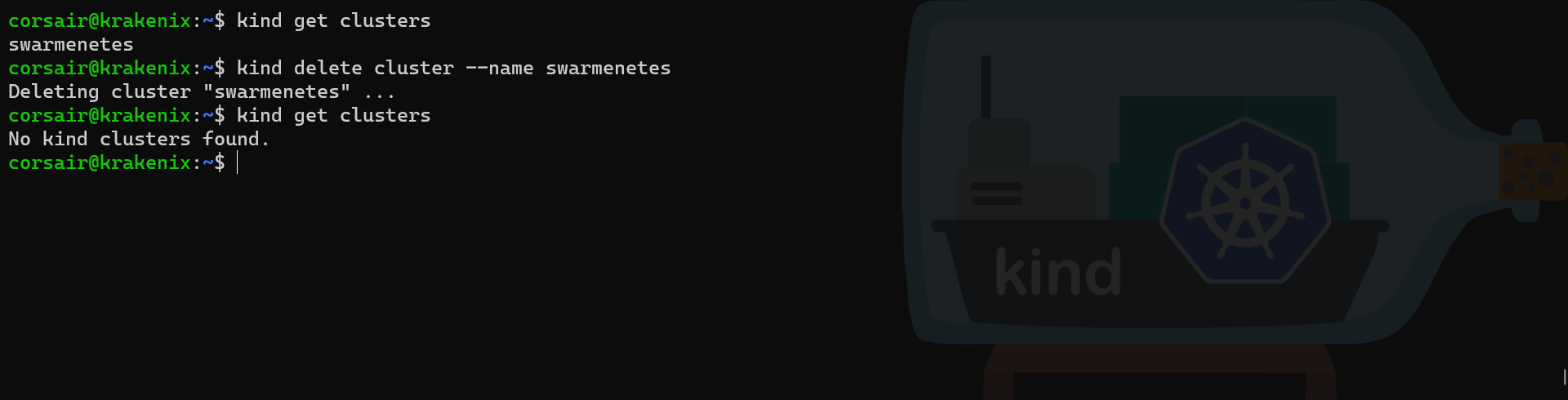
A multi-nodes on multi-hosts
Finally here and we will directly create a two nodes cluster on our manager nodes. And let us have a look on the last remaining part that will help us: attaching to a specific network when creating a KinD cluster.
KinD network: dancing with Dragons
Before we can create our new cluster, we need to see how we can use our Swarm network we created earlier.
Remember, this network will allow us to create the two clusters on different hosts and still using a unique network to communicate.
One more time, luckily for us, the KinD team already got a similar request and provided an experimental feature (cf. pkg/cluster/internal/providers/docker/provider.go):
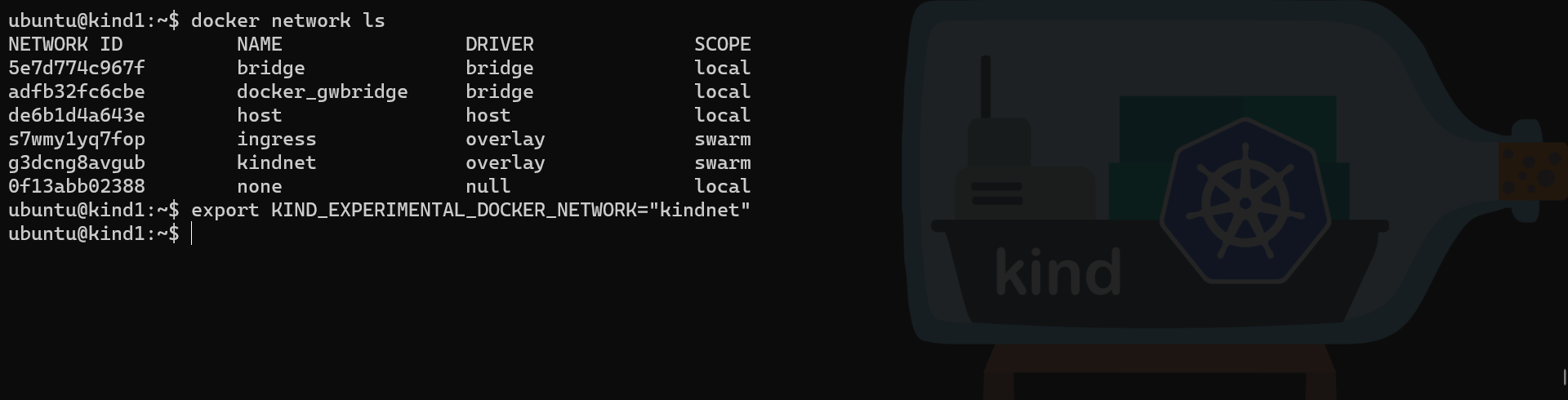
# Check the Docker networks
docker network ls
# Set the KinD network environment variable to the network name to be used
export KIND_EXPERIMENTAL_DOCKER_NETWORK="kindnet"
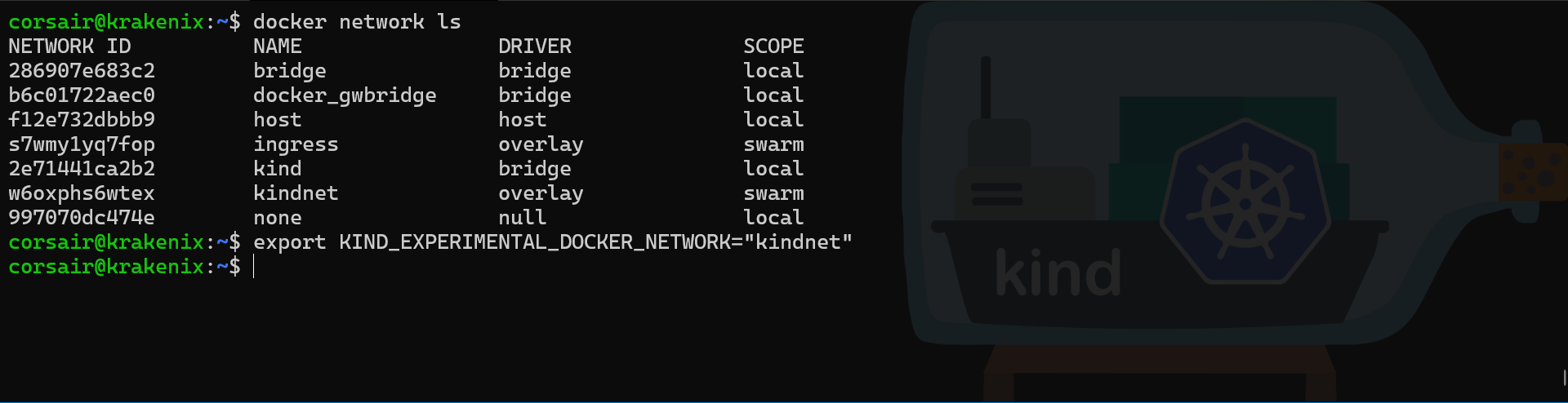
In order to save us time, we already know that we will need to run the exact same commands in our second node, so let us do it now:
# Check the Docker networks
docker network ls
# Set the KinD network environment variable to the network name to be used
export KIND_EXPERIMENTAL_DOCKER_NETWORK="kindnet"
Creating two KinD clusters
We can finally create our KinD clusters using our Swarm network. And for an easier management “later on”, we will also set a specific name to each one:
# Create a KinD cluster on the first node
kind create cluster --name swarmenetes
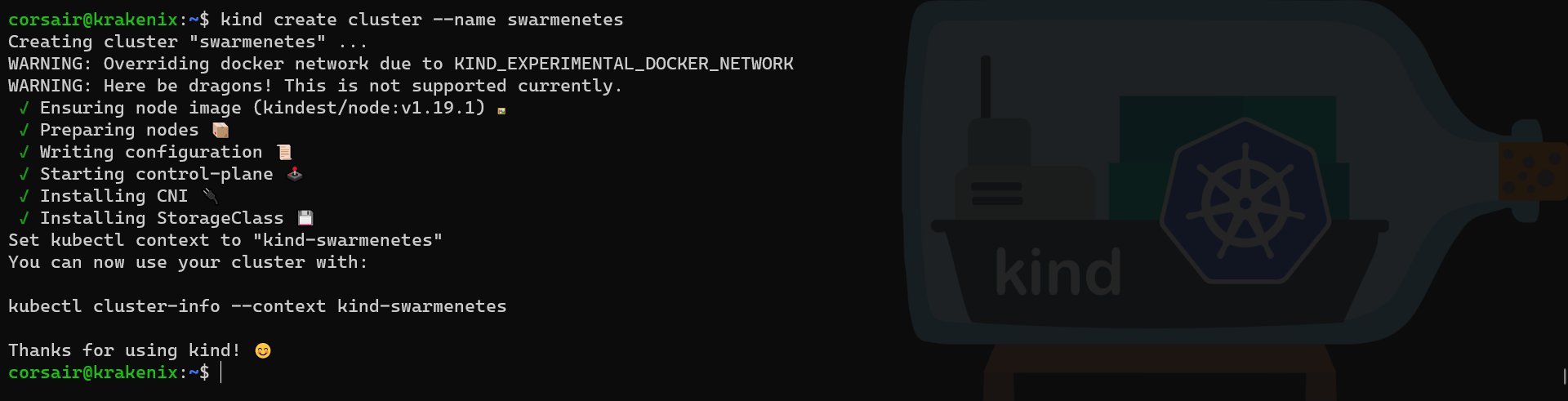
Note: as we can see, there is two warnings about using a specific Docker network
# Create a KinD cluster on the first node
kind create cluster --name swarmenetes-mate
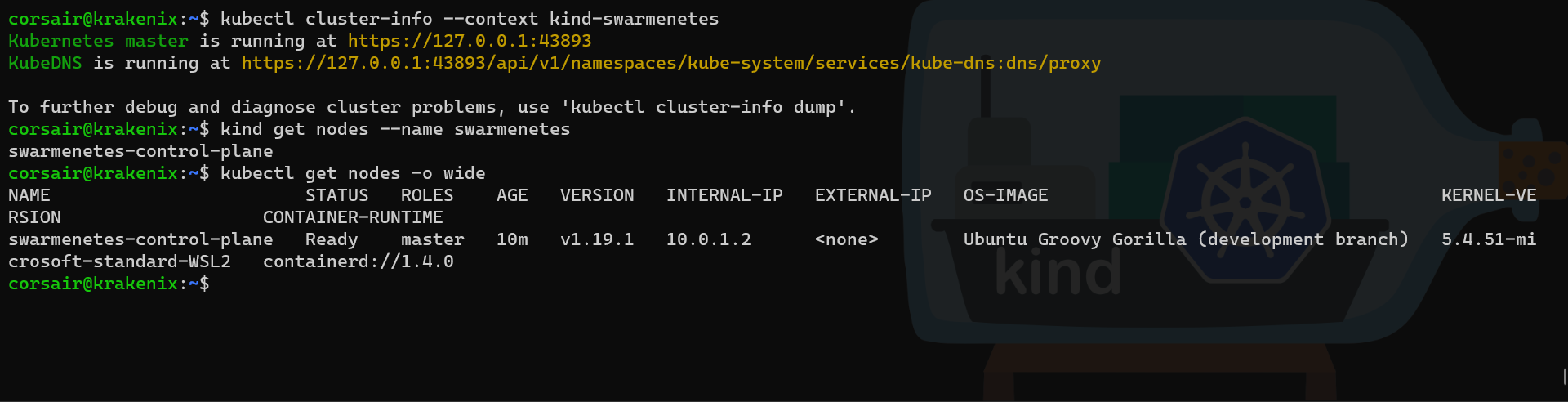
# Check if the cluster is running on the first node
kubectl cluster-info --context kind-swarmenetes
# Check the node from KinD perspective
kind get nodes --name swarmenetes
# Check the node from Kubernetes perspective with a detailed output
kubectl get nodes -o wide
# Check if the cluster is running on the second node
kubectl cluster-info --context kind-swarmenetes-mate
# Check the node from KinD perspective
kind get nodes --name swarmenetes-mate
# Check the node from Kubernetes perspective with a detailed output
kubectl get nodes -o wide
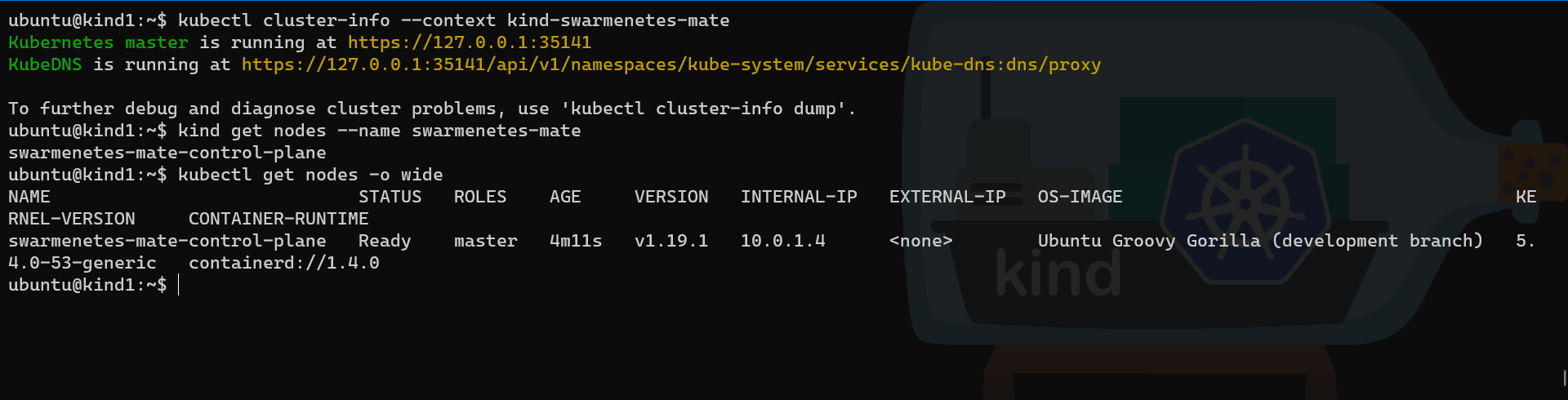
Our two clusters are up and running and if we look closely at the INTERNAL-IP values, we can see they are both on the same network subnet.
Let us do a quick check to see if it is the same network:
# Use curl to see if we get a response from the other node
curl -k https://10.0.1.4:6443
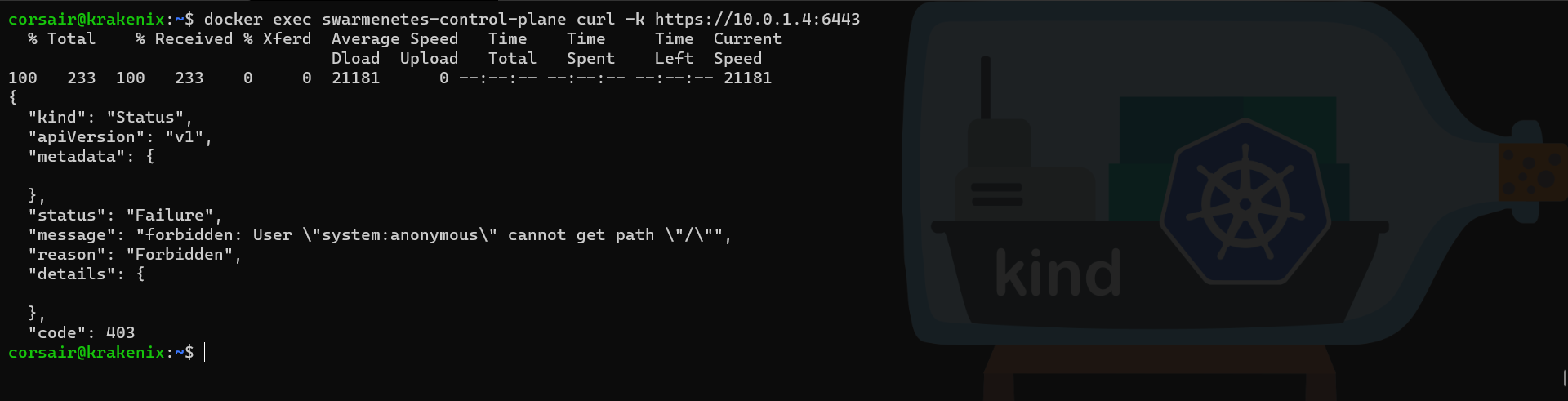
With the confirmation both clusters can communicate, we can reset our second node and join it to our cluster on the primary node.
What is the address name?
While our clusters can communicate using their respective IP addresses, they do not have “name resolving” to these specific addresses.
And as we saw in the join command that we generated “internally”, there was no IP address, just a “DNS name”. This means we will need to had this particular name to be resolved by our second node:
# Check the name of the container running on the primary node
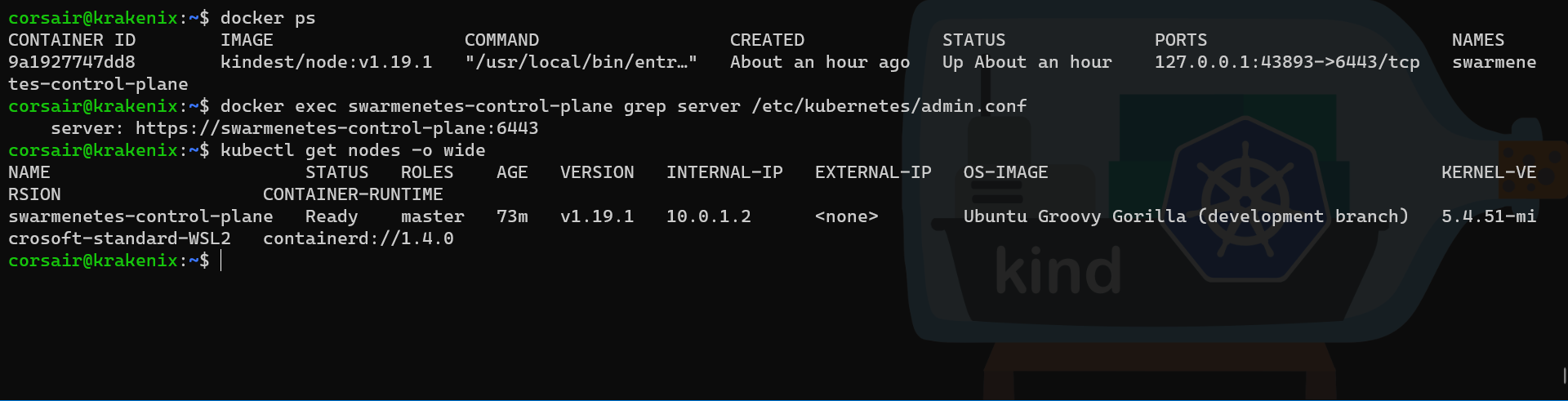
docker ps
# Get the server connection string from the "admin.conf" inside the container of the primary node
docker exec swarmenetes-control-plane grep server /etc/kubernetes/admin.conf
# Get the primary node IP from the Kubernetes detailed output
kubectl get nodes -o wide
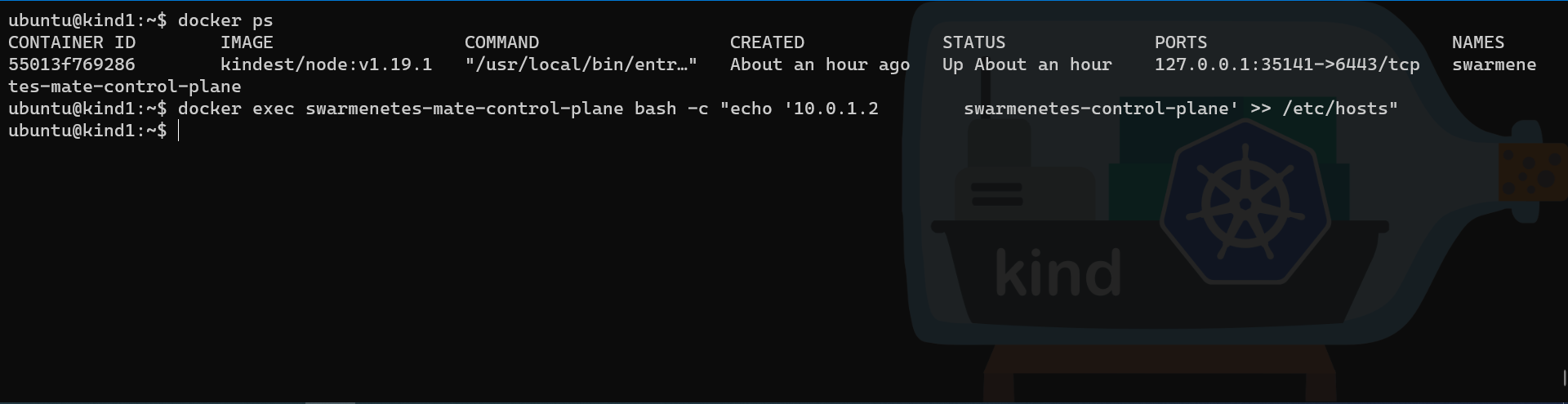
# Check the name of the container running on the second node
docker ps
# Add the DNS name and IP address to the /etc/hosts of the second node
docker exec swarmenetes-mate-control-plane bash -c "echo '10.0.1.2 swarmenetes-control-plane' >> /etc/hosts"
Reset before joining
Before we can run the join command against our cluster on the second node, we need to, literally, reset its configuration.
And to ensure the reset is “clean”, we will do it from within the container:
# Check the name of the container running on the second node
docker ps
# Reset the configuration of the cluster on the second node
docker exec swarmenetes-mate-control-plane kubeadm reset -f
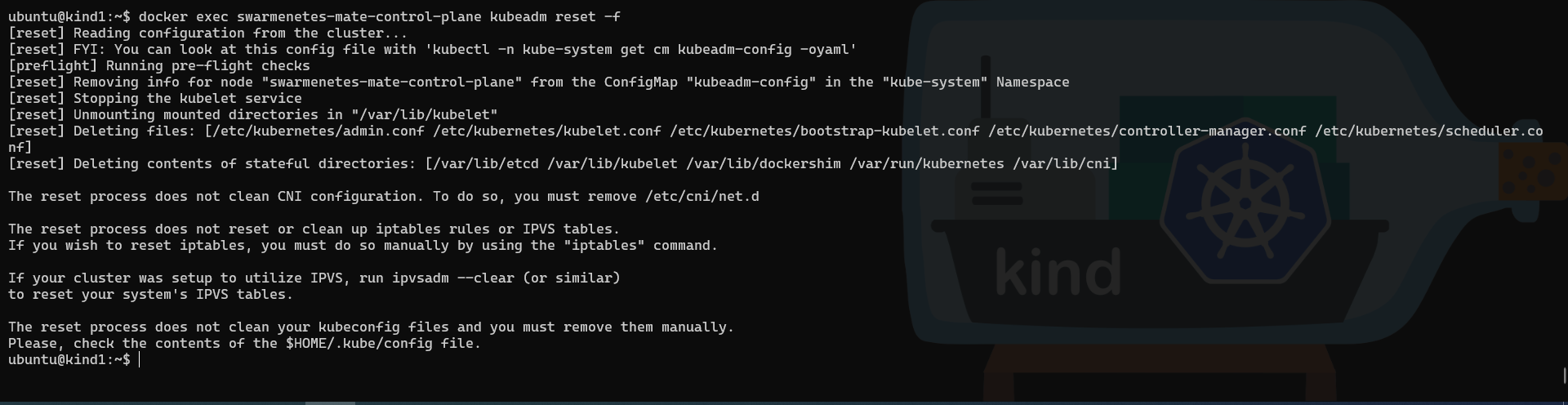
Now that our cluster is reset, we can get the join command from the cluster on the primary node and create our multi-nodes cluster.
And in the Swarm bind them
As seen during our tests on the single node cluster, we will need to run the join command within the containers hosting both manager nodes.
On our primary node, we can generate a new join command to be used on our second node cluster:
# Check the name of the container running on the primary node
docker ps
# Create a new join token from inside the container
docker exec swarmenetes-control-plane kubeadm token create --print-join-command
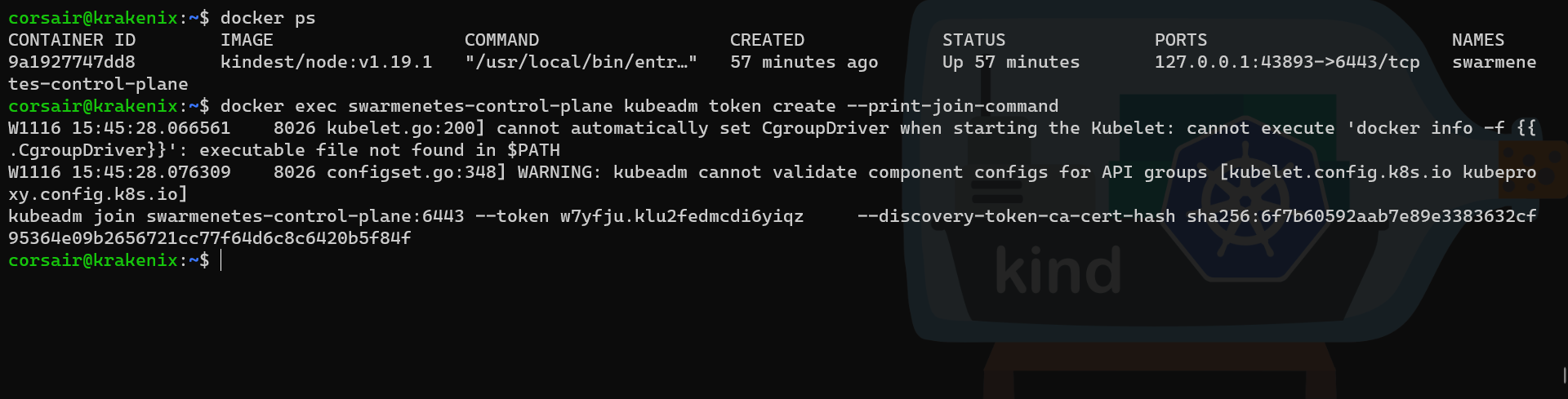
Then in our second node, we can run the join command:
# Check the name of the container running on the second node
docker ps
# Run the join command
docker exec swarmenetes-mate-control-plane kubeadm join swarmenetes-control-plane:6443 --token w7yfju.klu2fedmcdi6yiqz --dis
covery-token-ca-cert-hash sha256:6f7b60592aab7e89e3383632cf95364e09b2656721cc77f64d6c8c6420b5f84f --ignore-preflight-errors=all
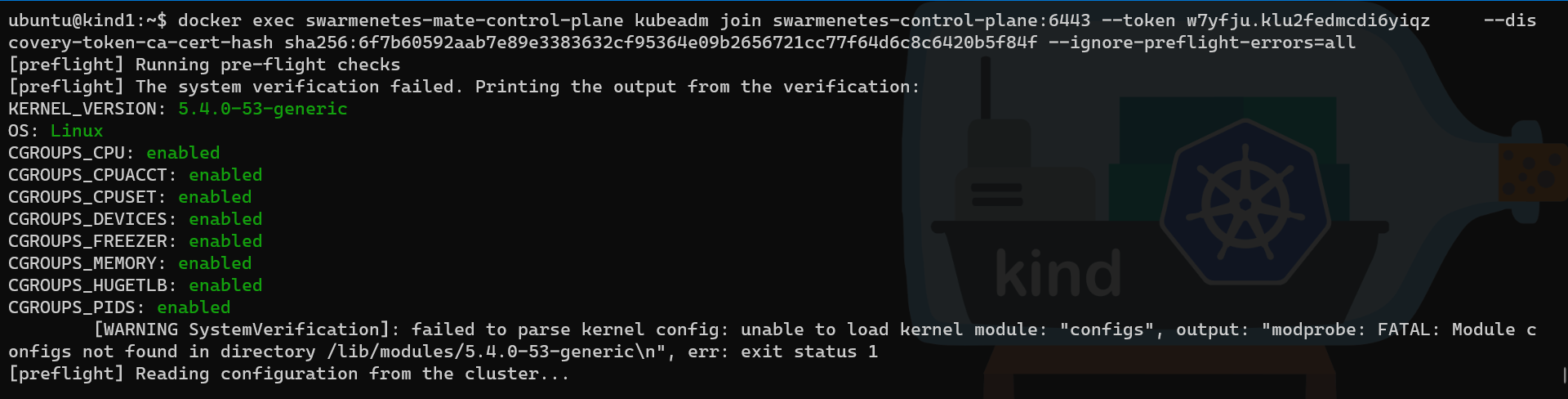
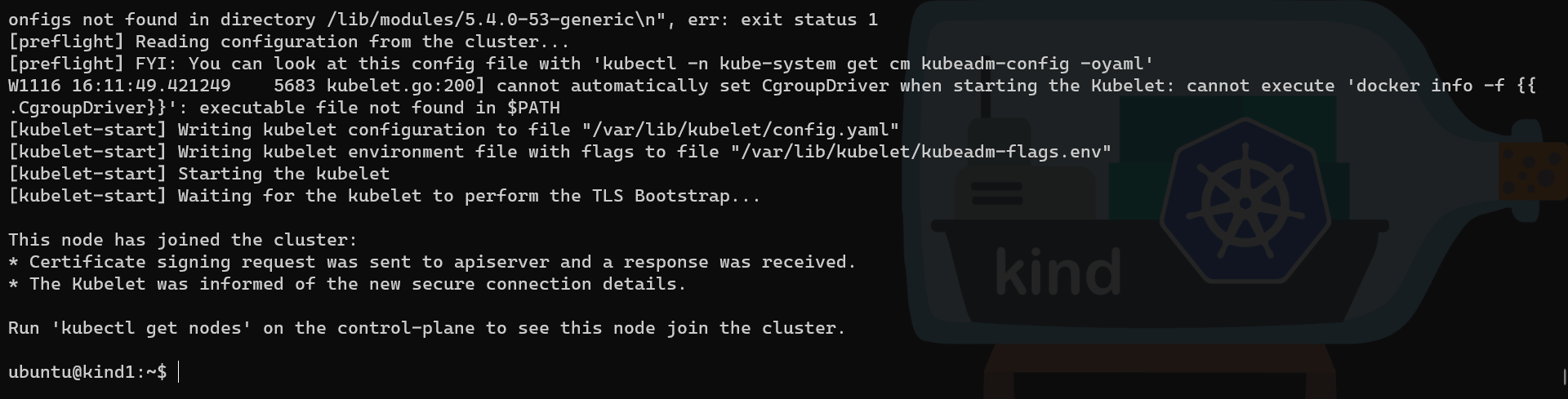
Note: as we can see in the first screenshot, the option “–ignore-preflight-errors=all” was added, as we are running K8s in a container and if we omit it, then the join command will fail
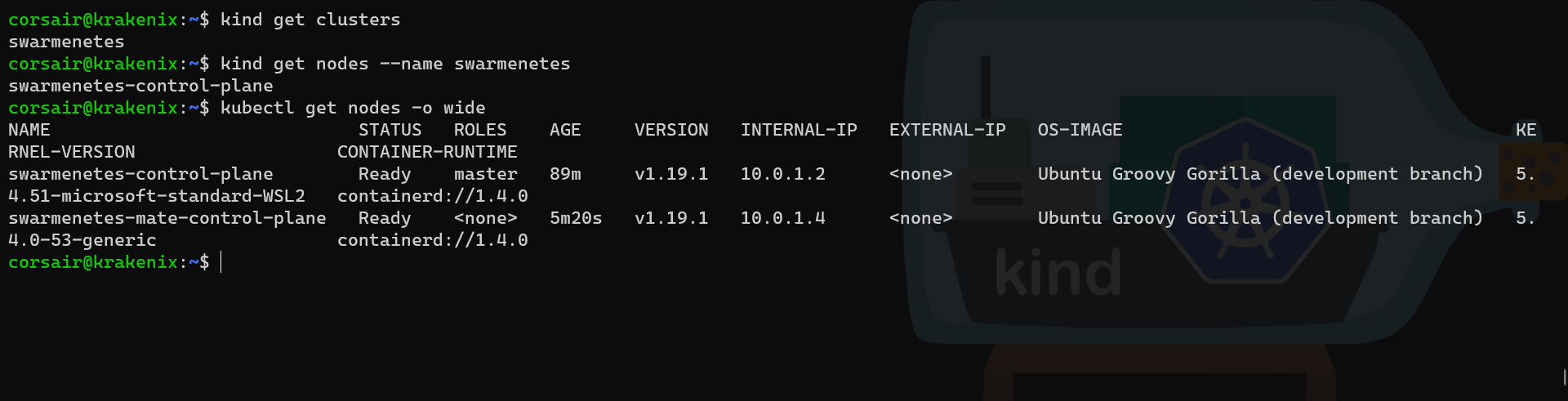
At the end of the command output, it suggests to run the kubectl get nodes on the control-plane, which is now our cluster in the primary node:
# Check the name of the cluster created
kind get clusters
# Check the node from KinD perspective
kind get nodes --name swarmenetes
# Check the node from Kubernetes perspective with a detailed output
kubectl get nodes -o wide
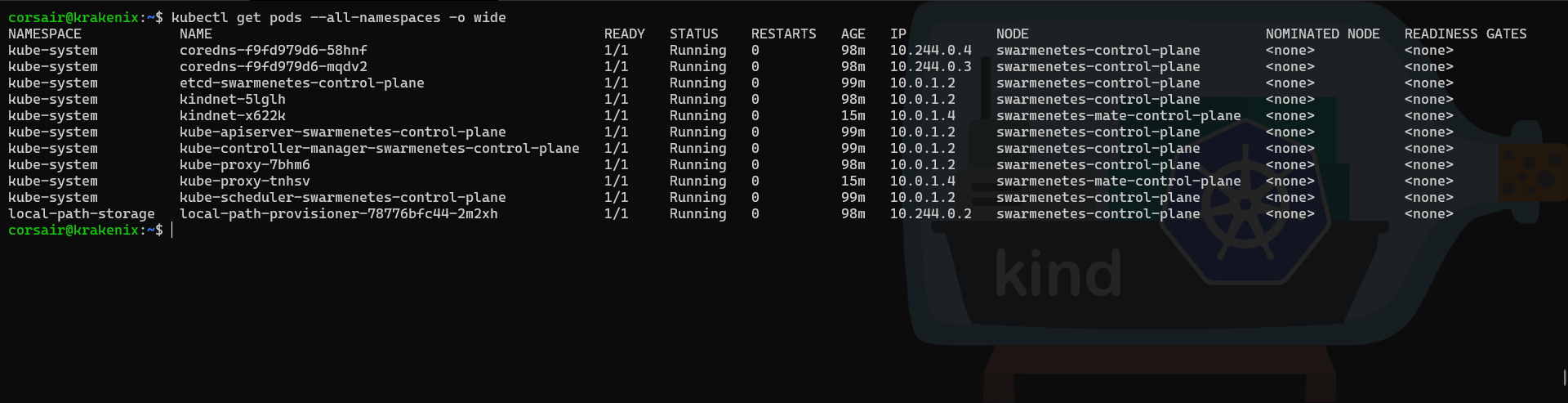
Let us also have a view at the pods created and their “placement”:
# Check the pods created
kubectl get pods --all-namespaces -o wide
And that concludes this (very?) lengthy but oh so fun blog.
Conclusion
When blogging about WSL and/or simply being part of this incredible community, we quickly learn we are now living in a world where “AND” is more powerful than “OR”.
The Cloud Native world is no different and I hope this blog post can show that when we mix different technologies, maybe, something totally cool (and potentially useless, I must admit) can be created.
And even if this blog is really not meant to be run elsewhere than on our own computer(s), the learning it provided for the different layers is the big gain, at least for me. And I really hope you will gain something from it too.
>>> Nunix out <<<
Bonus 1: Lessons learned “the Kelsey way”
Normally, as bonus sections we have additional steps for configuring or enable features. However, due to the (very) improbable setup we just did, there was its good share of lessons learned the (very) hard way and which are a perfect follow-up for this unusual blog post.
Lesson 1: reading the manual always comes too late
Let us start with what we could think about a “no brainer”: every time we want to implement something we first read the manual right? … right??
Well, yes we do, but certainly not extensively and while writing this blog post, it was no different. Initially, Docker Desktop was used for the WSL node. Everything in this blog was going just fine, until the Swarm cluster was needed.
Docker Desktop allows us to create a Swarm cluster … with a single node:
Currently, you cannot use Docker Desktop for Mac or Docker Desktop for Windows alone to test a multi-node swarm, but many examples are applicable to a single-node Swarm setup
If we look at the blog, this starts at “A Swarm-y network” and is about the middle of the blog. Which means, as you are guessing, the first half needed to be fully redone with Docker being installed directly on the WSL distro.
And the local install, on both nodes, lead to the second lesson.
Lesson 2: SNAP, I should use APT
If we look back at the prerequisites, we are using Ubuntu 20.04 as our WSL distro. Due to the current, and modified, init system used by WSL2, the default/standard install of a WSL distro does not load SystemD. That is why we went for a “normal” install using apt and not snap.
However, for the Multipass host, I taught it would have been a good learning and idea to show the snap install of Docker. Once again, that went well until the launch of KinD using the Swarm network we created as “attachable”. For whatever reason, the Docker refused to attach to the Swarm network.
This triggered a lot of creation/deletion of Swarm cluster and network, ensuring the nodes were connected, and while everything seemed OK, when trying to launch KinD with the network specified, it would fail.
Even worse, such blog is done over several days, so at some point we even tend to forget the way we installed software. So after some try/fail attempts, we need to get back to “basic” testing of all the components. In this particular case, if the cluster seemed OK, then it might be the software/OS underneath. And thankfully we had two nodes, so we could start comparing why the WSL node was working and not the Multipass.
The result was, as explained above, that Docker installed via snap could not (read: permission denied) connect to the Swarm network we created. The next obvious test was to uninstall the snap Docker package and install it from the “good old” apt repository.
Once done, everything worked as intended and a full subsection on installing Docker with snap was deleted.
Finally, all roadblocks were lifted and we could complete our cluster … or?
Lesson 3: Inception, which “dream” level are we on?
The last lesson learned while writing this blog came, once again, at a late stage when the need to join the second node. Thanks to Duffie, the join process was clear: reset the second node and run the join command with the kubeadm command.
And here started the learning, “where” should we run those commands? by default we want to use the kubectl and kubeadm commands on the same “inception level” KinD is installed. In our case, it is on WSL directly.
However, when trying to run the kubeadm token create --print-join-command, it would print the server connection string with the localhost address (read: 127.0.0.1) and a random port that would connect to the port 6443 port inside the container. As explained above, this address is unusable from the second node.
The first workaround tried, was to replace the localhost IP by the primary node IP and keep the port. That ended in a first failure about ports not open (etcd) and then about certificate mismatch.
This part, brought the biggest learnings on opening ports for etcd (2379, 2380) and using certificates alternate names (tls-san). And still, every single attempt failed. It was really OK to fail “that beautifully”, and end the blog post there by stating it was not possible, however how could we “abandon” so near of a solution.
And that’s when, the decision to go “deeper into one additional dream layer” was found. Inside the containers, we are at “ground zero” for the configurations and lucky for us, kubeadm was added to the KinD image by its maintainers.
The rest is in the blog and while luck and timing was on our side, if nobody provided a feedback about these features, then it would not have been possible to write this blog at the first place. So thank you to all OSS parties (users and maintainers) for allowing crazy blogs like this one to exist.